1.0 JAVA中的几种基本数据类型是什么,各自占用多少字节。
Java语言提供了八种基本类型。六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。
byte:
byte 数据类型是8位、有符号的,以二进制补码表示的整数;最小值是 -128(-2^7);最大值是 127(2^7-1);默认值是 0;byte 类型用在大型数组中节约空间,主要代替整数,因为 byte 变量占用的空间只有 int 类型的四分之一;例子:byte a = 100,byte b = -50。
short:
short 数据类型是 16 位、有符号的以二进制补码表示的整数最小值是 -32768(-2^15);最大值是 32767(2^15 - 1);Short 数据类型也可以像 byte 那样节省空间。一个short变量是int型变量所占空间的二分之一;默认值是 0;例子:short s = 1000,short r = -20000。
int:
int 数据类型是32位、有符号的以二进制补码表示的整数;最小值是 -2,147,483,648(-2^31);最大值是 2,147,483,647(2^31 - 1);一般地整型变量默认为 int 类型;默认值是 0 ;例子:int a = 100000, int b = -200000。
long:
long 数据类型是 64 位、有符号的以二进制补码表示的整数;最小值是 -9,223,372,036,854,775,808(-2^63);最大值是 9,223,372,036,854,775,807(2^63 -1);这种类型主要使用在需要比较大整数的系统上;默认值是 0L;例子:long a = 100000L,Long b = -200000L。”L”理论上不分大小写,但是若写成”l”容易与数字”1”混淆,不容易分辩。所以最好大写。
float:
float 数据类型是单精度、32位、符合IEEE 754标准的浮点数;float 在储存大型浮点数组的时候可节省内存空间;默认值是 0.0f;浮点数不能用来表示精确的值,如货币;例子:float f1 = 234.5f。
double:
double 数据类型是双精度、64 位、符合IEEE 754标准的浮点数;浮点数的默认类型为double类型;double类型同样不能表示精确的值,如货币;默认值是 0.0d;例子:double d1 = 123.4。
boolean:
boolean数据类型表示一位的信息;只有两个取值:true 和 false;这种类型只作为一种标志来记录 true/false 情况;默认值是 false;例子:boolean one = true。
char:
char类型是一个单一的 16 位 Unicode 字符;最小值是 \u0000(即为0);最大值是 \uffff(即为65,535);char 数据类型可以储存任何字符;例子:char letter = 'A';。
1.1 String类能被继承吗,为什么。
不能
大白话解释就是:String很多实用的特性,比如说“不可变性”,是工程师精心设计的艺术品!艺术品易碎!用final就是拒绝继承,防止世界被熊孩子破坏,维护世界和平!
PS:String基本约定中最重要的一条是immutable,声明String为final 和immutable虽然没有必然关系,但是假如String没有声明为final, 那么StringChilld就有可能是被复写为mutable的,这样就打破了成为共识的基本约定。要知道,String是几乎每个类都会使用的类,特别是作为Hashmap之类的集合的key值时候,mutable的String有非常大的风险。而且一旦发生,非常难发现。声明String为final一劳永逸。
Why String is Immutable or Final in Java
1.2 String,Stringbuffer,StringBuilder的区别。
可变性
String是不可变的,它使用final关键词修饰
1 | public final class String |
StringBuffer和StringBuilder两者都是继承自AbstractStringBuilder,AbstractStringBuilder也是用字符数组保存char value[],但是没有用final修饰,所以这两种对象是可变的
1 | public final class StringBuffer |
线程安全性
String的对象不可变,也就是常量,所以线程安全
StringBuffer重写了AbstractStringBuilder的方法,比如append、insert等并且加了同步锁,所以是线程安全的
1 |
|
而StringBuilder就没加同步锁,所以是非线程安全的
性能
每次修改String的值都会重新生成一个新的String对象,然后再将指针指向新的String对象,StringBuffer和StringBuilder每次都是对象本身进行操作,而不是生成新的对象。StringBuilder的性能会比StringBuffer好一点,不过却要冒多线程不安全的风险
总结
- 数据量少多用String
- 单线程操作大量数据用StringBuilder
- 多线程操作大量数据用StringBuffer
1.3 ArrayList和LinkedList有什么区别。
ArrayList的实现用的是数组,LinkedList是基于链表,ArrayList适合查找,LinkedList适合增删
ArrayList
ArrayList:内部使用数组的形式实现了存储,实现了RandomAccess接口,利用数组的下标进行元素的访问,因此对元素的随机访问速度非常快。
因为是数组,所以ArrayList在初始化的时候,有初始大小10,插入新元素的时候,会判断是否需要扩容,扩容的步长是0.5倍原容量,扩容方式是利用数组的复制,因此有一定的开销;
另外,ArrayList在进行元素插入的时候,需要移动插入位置之后的所有元素,位置越靠前,需要位移的元素越多,开销越大,相反,插入位置越靠后的话,开销就越小了,如果在最后面进行插入,那就不需要进行位移;
LinkedList
LinkedList:内部使用双向链表的结构实现存储,LinkedList有一个内部类作为存放元素的单元,里面有三个属性,用来存放元素本身以及前后2个单元的引用,另外LinkedList内部还有一个header属性,用来标识起始位置,LinkedList的第一个单元和最后一个单元都会指向header,因此形成了一个双向的链表结构。
LinkedList是采用双向链表实现的。所以它也具有链表的特点,每一个元素(结点)的地址不连续,通过引用找到当前结点的上一个结点和下一个结点,即插入和删除效率较高,只需要常数时间,而get和set则较为低效。
LinkedList的方法和使用和ArrayList大致相同,由于LinkedList是链表实现的,所以额外提供了在头部和尾部添加/删除元素的方法,也没有ArrayList扩容的问题了。另外,ArrayList和LinkedList都可以实现栈、队列等数据结构,但LinkedList本身实现了队列的接口,所以更推荐用LinkedList来实现队列和栈。
综上所述,在需要频繁读取集合中的元素时,使用ArrayList效率较高,而在插入和删除操作较多时,使用LinkedList效率较高。
1.4 讲讲类的实例化顺序,比如父类静态数据,构造函数,字段,子类静态数据,构造函数,字段,当new的时候,他们的执行顺序。
初始化顺序:父类static静态变量 > 父类static代码块 > 子类static静态变量 > 子类static代码块 > 父类变量 > 父类实例代码块 > 父类构造函数 > 子类变量 > 子类实例代码块 > 子类构造函数
1.5 用过哪些Map类,都有什么区别,HashMap是线程安全的吗,并发下使用的Map是什么,他们内部原理分别是什么,比如存储方式,hashcode,扩容,默认容量等。
最常用的Map实现类有:HashMap,ConcurrentHashMap(jdk1.8),LinkedHashMap,TreeMap,HashTable;
其中最频繁的是HashMap和ConcurrentHashMap,他们的主要区别是HashMap是非线程安全的。ConcurrentHashMap是线程安全的。并发下可以使用ConcurrentHashMap和HashTable
1.HashMap
存储原理就是散列表
散列函数的设计不能太复杂,生成的值要尽可能随机并且均匀分布
HashMap使用高低16位异或对数组长度取余符合这个规则:
1 | static final int hash(Object key) { |
- 散列冲突
HashMap使用链表解决Hash冲突,相较开放寻址法更加节约内存,而且方便通过其它数据结构进行优化,比如JDK1.8就是使用红黑树优化,防止Hash攻击。 - 动态扩容
HashMap的默认阈值是0.75,数组长度默认是16,以2的倍数增长,方便取余,美中不足的是,HashMap的扩容是一步到位的,虽然均摊时间复杂度不高,但是可能扩容的那次put会比较慢,可以考虑高效扩容(装载因子触达阈值时,只申请新空间,不搬运数据,之后每插入一个新数据我们从旧散列表拿一个旧数据放到新散列表,可以在新散列表到达阈值前搬运完毕,利用了扩容后装载因子减半的特性。);
2.ConcurrentHashMap和hashtable的区别
ConcurrentHashMap的hash计算公式:(key.hascode()^ (key.hascode()>>> 16)) & 0x7FFFFFFF
HashTable的hash计算公式:key.hascode()& 0x7FFFFFFF
HashTable存储方式都是链表+数组,数组里面放的是当前hash的第一个数据,链表里面放的是hash冲突的数据
ConcurrentHashMap是数组+链表+红黑树
默认容量都是16,负载因子是0.75。就是当hashmap填充了75%的busket是就会扩容,最小的可能性是(16*0.75),一般为原内存的2倍
线程安全的保证:HashTable是在每个操作方法上面加了synchronized来达到线程安全,ConcurrentHashMap线程是使用CAS(compore and swap)来保证线程安全的
ConcurrentHashMap内部原理
1.7: put 加锁
通过分段加锁 segment,put 数据时通过 hash(key) 得到该元素要添加到的 segment,对 segment 进行加锁,进行再 hash 得到该元素要添加到的桶,遍历桶中的链表,替换或新增节点到桶中。
1.8: put CAS 加锁
1.8 中仍然有 segment 的定义,但不再有任何结构上的用处,segment 数量与桶数量一致,不依赖于 segment 加锁。
首先,判断容器是否为空,如果为空则进行初始化,否则重试对 hash(key) 计算得到该 key 存放的桶位置,判断该桶是否为空,为空则利用 CAS 设置新节点,否则使用 synchronized 加锁,遍历桶中数据,替换或新增加节点到桶中,最后判断是否需要转为红黑树,转换之前判断是否需要扩容。
3.HashMap细节
构造参数传进的初始化容量是怎么“向上取整”的?
通过 n |= n >>> (1,2,4,8,16)的方式,使得低位全部填满1,最后再+1就是我们说的数组长度是2的幂。
1 | /** |
JDK1.8,并发编程不再死循环
旧的HashMap扩容的时候链是反过来的,比如说本来是a->b->c,先取a放到新的数组,再取b放过去就成了b->a,加上c就是c->b->a,可以看见引用反过来了,并发编程的时候,容易造成循环引用,也就是老生常谈的死循环。
到了1.8就不这么干了,通过(e.hash & oldCap) == 0去区分扩容后新节点位置可以说是非常精妙了,我是愣了一下才想明白,然后分两条链,顺序的,比如说原来时a->b->c-d,分开之后可能就变成a->c和a->d,这样依赖就不存在循环引用了,而且还最大程度维护了原来的顺序。
不过这个死循环BUG是因为会强占太多CPU资源被重视,而后又被妖魔化,HashMap本来就不是并发编程的容器,用在并发编程上总会有各种各样的问题,所以在这点上研究价值大于实用价值,毕竟没谁会直接在并发编程下怼一个HashMap上去吧。
1 | Node<K,V> loHead = null, loTail = null; |
put()操作的伪代码
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
尝试用伪代码表达它的逻辑:
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
1.6 JAVA8的ConcurrentHashMap为什么放弃了分段锁,有什么问题吗,如果你来设计,你如何设计。
弃用原因
通过 JDK 的源码和官方文档看来, 他们认为的弃用分段锁的原因由以下几点:
- 加入多个分段锁浪费内存空间。
- 生产环境中, map 在放入时竞争同一个锁的概率非常小,分段锁反而会造成更新等操作的长时间等待。
- 为了提高 GC 的效率
PS:关于Segment
ConcurrentHashMap有3个参数:
- initialCapacity:初始总容量,默认16
- loadFactor:加载因子,默认0.75
- concurrencyLevel:并发级别,默认16
其中并发级别控制了Segment的个数,在一个ConcurrentHashMap创建后Segment的个数是不能变的,扩容过程过改变的是每个Segment的大小。
PS:关于分段锁
段Segment继承了重入锁ReentrantLock,有了锁的功能,每个锁控制的是一段,当每个Segment越来越大时,锁的粒度就变得有些大了。
- 分段锁的优势在于保证在操作不同段 map 的时候可以并发执行,操作同段 map 的时候,进行锁的竞争和等待。这相对于直接对整个map同步synchronized是有优势的。
- 缺点在于分成很多段时会比较浪费内存空间(不连续,碎片化); 操作map时竞争同一个分段锁的概率非常小时,分段锁反而会造成更新等操作的长时间等待; 当某个段很大时,分段锁的性能会下降。
新的同步方案
既然弃用了分段锁, 那么一定由新的线程安全方案, 我们来看看源码是怎么解决线程安全的呢?(源码保留了segment 代码, 但并没有使用,只是为了兼容旧版本)
和hashmap一样,jdk 1.8中ConcurrentHashmap采用的底层数据结构为数组+链表+红黑树的形式。数组可以扩容,链表可以转化为红黑树。
什么时候扩容?
- 当前容量超过阈值
- 当链表中元素个数超过默认设定(8个),当数组的大小还未超过64的时候,此时进行数组的扩容,如果超过则将链表转化成红黑树
什么时候链表转化为红黑树?
当数组大小已经超过64并且链表中的元素个数超过默认设定(8个)时,将链表转化为红黑树
put
首先通过 hash 找到对应链表过后, 查看是否是第一个object, 如果是, 直接用cas原则插入,无需加锁。
1 | Node<K,V> f; int n, i, fh; K fk; V fv; |
然后, 如果不是链表第一个object, 则直接用链表第一个object加锁,这里加的锁是synchronized,虽然效率不如 ReentrantLock, 但节约了空间,这里会一直用第一个object为锁, 直到重新计算map大小, 比如扩容或者操作了第一个object为止。
1 | synchronized (f) {// 这里的f即为第一个链表的object |
为什么不用ReentrantLock而用synchronized ?
- 减少内存开销:如果使用ReentrantLock则需要节点继承AQS来获得同步支持,增加内存开销,而1.8中只有头节点需要进行同步。
- 内部优化:synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。
1.7 有没有有顺序的Map实现类,如果有,他们是怎么保证有序的。
TreeMap和LinkedHashMap是有序的(TreeMap默认升序,LinkedHashMap则记录了插入顺序)。
HashMap:
put -> addEntry(新建一个Entry)
get
getEntry
LinkedHashMap:
put -> addEntry(重写)
新建一个Entry,然后将其加入header前
e.addBefore(header)
get -> 调用HashMap的getEntry - recordAccess(重写)
HashMap的get与getEntry
1 | final Entry<K,V> getEntry(Object key) { |
- LinkedHashMap概述:
LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。
LinkedHashMap是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用get方法)的链表。
默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。 可以重写removeEldestEntry方法返回true值指定插入元素时移除最老的元素。
- LinkedHashMap的实现:
对于LinkedHashMap而言,它继承与HashMap、底层使用哈希表与双向链表来保存所有元素。其基本操作与父类HashMap相似,它通过重写父类相关的方法,来实现自己的链接列表特性。下面我们来分析LinkedHashMap的源代码:
类结构:
1 | public class LinkedHashMap<K, V> extends HashMap<K, V> implements Map<K, V> |
1) 成员变量:
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了数组中保存的元素Entry,该Entry除了保存当前对象的引用外,还保存了其上一个元素before和下一个元素after的引用,从而在哈希表的基础上又构成了双向链接列表。看源代码:
1 | //true表示按照访问顺序迭代,false时表示按照插入顺序 |
HashMap.Entry:
1 | static class Entry<K,V> implements Map.Entry<K,V> { |
2) 初始化:
通过源代码可以看出,在LinkedHashMap的构造方法中,实际调用了父类HashMap的相关构造方法来构造一个底层存放的table数组。如:
1 | public LinkedHashMap(int initialCapacity, float loadFactor) { |
HashMap中的相关构造方法:
1 | public HashMap(int initialCapacity, float loadFactor) { |
我们已经知道LinkedHashMap的Entry元素继承HashMap的Entry,提供了双向链表的功能。在上述HashMap的构造器中,最后会调用init()方法,进行相关的初始化,这个方法在HashMap的实现中并无意义,只是提供给子类实现相关的初始化调用。
LinkedHashMap重写了init()方法,在调用父类的构造方法完成构造后,进一步实现了对其元素Entry的初始化操作。
1 | void init() { |
3) 存储:
LinkedHashMap并未重写父类HashMap的put方法,而是重写了父类HashMap的put方法调用的子方法void recordAccess(HashMap m) ,void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex),提供了自己特有的双向链接列表的实现。
HashMap.put:
1 | public V put(K key, V value) { |
重写方法:
1 | void recordAccess(HashMap<K,V> m) { |
4) 读取:
LinkedHashMap重写了父类HashMap的get方法,实际在调用父类getEntry()方法取得查找的元素后,再判断当排序模式accessOrder为true时,记录访问顺序,将最新访问的元素添加到双向链表的表头,并从原来的位置删除。由于的链表的增加、删除操作是常量级的,故并不会带来性能的损失。
HashMap.containsValue:
1 | public boolean containsValue(Object value) { |
5) 排序模式:
LinkedHashMap定义了排序模式accessOrder,该属性为boolean型变量,对于访问顺序,为true;对于插入顺序,则为false。
1 | private final boolean accessOrder; |
一般情况下,不必指定排序模式,其迭代顺序即为默认为插入顺序。看LinkedHashMap的构造方法,如:
1 | public LinkedHashMap(int initialCapacity, float loadFactor) { |
这些构造方法都会默认指定排序模式为插入顺序。如果你想构造一个LinkedHashMap,并打算按从近期访问最少到近期访问最多的顺序(即访问顺序)来保存元素,那么请使用下面的构造方法构造LinkedHashMap:
1 | public LinkedHashMap(int initialCapacity, |
该哈希映射的迭代顺序就是最后访问其条目的顺序,这种映射很适合构建LRU缓存。LinkedHashMap提供了removeEldestEntry(Map.Entry<K,V> eldest)方法。该方法可以提供在每次添加新条目时移除最旧条目的实现程序,默认返回false,这样,此映射的行为将类似于正常映射,即永远不能移除最旧的元素。
当有新元素加入Map的时候会调用Entry的addEntry方法,会调用removeEldestEntry方法,这里就是实现LRU元素过期机制的地方,默认的情况下removeEldestEntry方法只返回false表示元素永远不过期。
1 | /** |
此方法通常不以任何方式修改映射,相反允许映射在其返回值的指引下进行自我修改。如果用此映射构建LRU缓存,则非常方便,它允许映射通过删除旧条目来减少内存损耗。
例如:重写此方法,维持此映射只保存100个条目的稳定状态,在每次添加新条目时删除最旧的条目。
1 | private static final int MAX_ENTRIES = 100; |
其实LinkedHashMap几乎和HashMap一样,不同的是它定义了一个Entry<K,V> header,这个header不是放在Table里,它是额外独立出来的。LinkedHashMap通过继承hashMap中的Entry<K,V>,并添加两个属性Entry<K,V> before,after,和header结合起来组成一个双向链表,来实现按插入顺序或访问顺序排序。
1.8 抽象类和接口的区别,类可以继承多个类么,接口可以继承多个接口么,类可以实现多个接口么。
1、抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象。
2、抽象类要被子类继承,接口要被类实现。
3、接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现
4、接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。
5、抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
6、抽象方法只能申明,不能实现。abstract void abc();不能写成abstract void abc(){}。
7、抽象类里可以没有抽象方法
8、如果一个类里有抽象方法,那么这个类只能是抽象类
9、抽象方法要被实现,所以不能是静态的,也不能是私有的。
10、接口可继承接口,并可多继承接口,但类只能单根继承。
| 参数 | 抽象类 | 接口 |
|---|---|---|
| 默认的方法实现 | 它可以有默认的方法实现 | 接口完全是抽象的。它根本不存在方法的实现 |
| 关键字 | 子类使用extends关键字来继承抽象类。如果子类不是抽象类的话,它需要提供抽象类中所有声明的方法的实现。 | 子类使用关键字implements来实现接口。它需要提供接口中所有声明的方法的实现 |
| 构造器 | 抽象类可以有构造器 | 接口不能有构造器 |
| 与正常Java类的区别 | 除了你不能实例化抽象类之外,它和普通Java类没有任何区别 | 接口是完全不同的类型 |
| 访问修饰符 | 抽象方法可以有public、protected和default这些修饰符 | 接口方法默认修饰符是public。你不可以使用其它修饰符。 |
| main方法 | 抽象方法可以有main方法并且我们可以运行它 | 接口没有main方法,因此我们不能运行它。 |
| 多继承 | 抽象类只可以继承一个类和实现多个接口 | 接口和接口之间是可以多继承或者单继承多实现的。 |
| 速度 | 它比接口速度要快 | 接口是稍微有点慢的,因为它需要时间去寻找在类中实现的方法。 |
| 添加新方法 | 如果你往抽象类中添加新的方法,你可以给它提供默认的实现。因此你不需要改变你现在的代码。 | 如果你往接口中添加方法,那么你必须改变实现该接口的类。 |
| 设计理念 | is-a的关系,体现的是一种关系的延续 | like-a体现的是一种功能的扩展关系 |
具体使用的场景
- 如果你拥有一些方法并且想让它们中的一些有默认实现,那么使用抽象类吧。
- 如果你想实现多重继承,那么你必须使用接口。由于Java不支持多继承,子类不能够继承多个类,但可以实现多个接口。因此你就可以使用接口来解决它。
- 如果基本功能在不断改变,那么就需要使用抽象类。如果不断改变基本功能并且使用接口,那么就需要改变所有实现了该接口的类。
- 多用组合,少用继承。
1.9 继承和聚合的区别在哪。
继承指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;在Java中此类关系通过关键字extends明确标识,在设计时一般没有争议性;
聚合是关联关系的一种特例,他体现的是整体与部分、拥有的关系,即has-a的关系,此时整体与部分之间是可分离的,他们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享;比如计算机与CPU、公司与员工的关系等;表现在代码层面,和关联关系是一致的,只能从语义级别来区分
2.0 IO模型有哪些,讲讲你理解的nio ,他和bio,aio的区别是啥,谈谈reactor模型。
IO是面向流的,NIO是面向缓冲区的
NIO(Non-blocking I/O,在Java领域,也称为New I/O),是一种同步非阻塞的I/O模型,也是I/O多路复用的基础,已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O处理问题的有效方式。
传统BIO模型分析
让我们先回忆一下传统的服务器端同步阻塞I/O处理(也就是BIO,Blocking I/O)的经典编程模型:
1 | { |
这是一个经典的每连接每线程的模型,之所以使用多线程,主要原因在于socket.accept()、socket.read()、socket.write()三个主要函数都是同步阻塞的,当一个连接在处理I/O的时候,系统是阻塞的,如果是单线程的话必然就挂死在那里;但CPU是被释放出来的,开启多线程,就可以让CPU去处理更多的事情。其实这也是所有使用多线程的本质:
- 利用多核。
- 当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。
现在的多线程一般都使用线程池,可以让线程的创建和回收成本相对较低。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的I/O并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。
不过,这个模型最本质的问题在于,严重依赖于线程。但线程是很”贵”的资源,主要表现在:
- 线程的创建和销毁成本很高,在Linux这样的操作系统中,线程本质上就是一个进程。创建和销毁都是重量级的系统函数。
- 线程本身占用较大内存,像Java的线程栈,一般至少分配512K~1M的空间,如果系统中的线程数过千,恐怕整个JVM的内存都会被吃掉一半。
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统load偏高、CPU sy使用率特别高(超过20%以上),导致系统几乎陷入不可用的状态。
- 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
所以,当面对十万甚至百万级连接的时候,传统的BIO模型是无能为力的。随着移动端应用的兴起和各种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的I/O处理模型。
NIO是怎么工作的
很多刚接触NIO的人,第一眼看到的就是Java相对晦涩的API,比如:Channel,Selector,Socket什么的;然后就是一坨上百行的代码来演示NIO的服务端Demo……瞬间头大有没有?
我们不管这些,抛开现象看本质,先分析下NIO是怎么工作的。
常见I/O模型对比
所有的系统I/O都分为两个阶段:等待就绪和操作。举例来说,读函数,分为等待系统可读和真正的读;同理,写函数分为等待网卡可以写和真正的写。
需要说明的是等待就绪的阻塞是不使用CPU的,是在“空等”;而真正的读写操作的阻塞是使用CPU的,真正在”干活”,而且这个过程非常快,属于memory copy,带宽通常在1GB/s级别以上,可以理解为基本不耗时。
下图是几种常见I/O模型的对比:
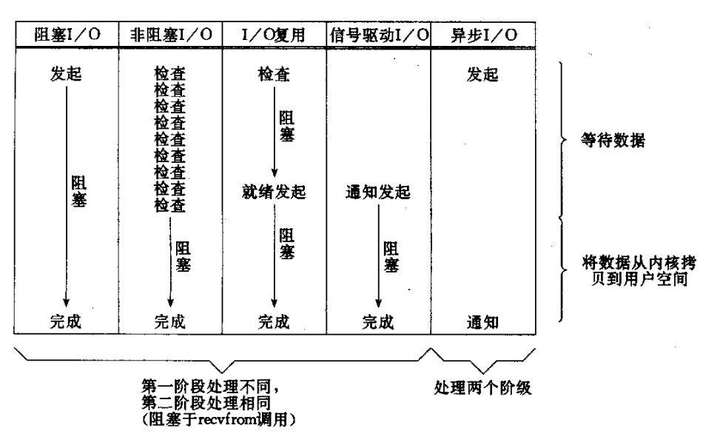
以socket.read()为例子:
传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据,返回读到的数据。
对于NIO,如果TCP RecvBuffer有数据,就把数据从网卡读到内存,并且返回给用户;反之则直接返回0,永远不会阻塞。
最新的AIO(Async I/O)里面会更进一步:不但等待就绪是非阻塞的,就连数据从网卡到内存的过程也是异步的。
换句话说,BIO里用户最关心“我要读”,NIO里用户最关心”我可以读了”,在AIO模型里用户更需要关注的是“读完了”。
NIO一个重要的特点是:socket主要的读、写、注册和接收函数,在等待就绪阶段都是非阻塞的,真正的I/O操作是同步阻塞的(消耗CPU但性能非常高)。
如何结合事件模型使用NIO同步非阻塞特性
回忆BIO模型,之所以需要多线程,是因为在进行I/O操作的时候,一是没有办法知道到底能不能写、能不能读,只能”傻等”,即使通过各种估算,算出来操作系统没有能力进行读写,也没法在socket.read()和socket.write()函数中返回,这两个函数无法进行有效的中断。所以除了多开线程另起炉灶,没有好的办法利用CPU。
NIO的读写函数可以立刻返回,这就给了我们不开线程利用CPU的最好机会:如果一个连接不能读写(socket.read()返回0或者socket.write()返回0),我们可以把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。
下面具体看下如何利用事件模型单线程处理所有I/O请求:
NIO的主要事件有几个:读就绪、写就绪、有新连接到来。
我们首先需要注册当这几个事件到来的时候所对应的处理器。然后在合适的时机告诉事件选择器:我对这个事件感兴趣。对于写操作,就是写不出去的时候对写事件感兴趣;对于读操作,就是完成连接和系统没有办法承载新读入的数据的时;对于accept,一般是服务器刚启动的时候;而对于connect,一般是connect失败需要重连或者直接异步调用connect的时候。
其次,用一个死循环选择就绪的事件,会执行系统调用(Linux 2.6之前是select、poll,2.6之后是epoll,Windows是IOCP),还会阻塞的等待新事件的到来。新事件到来的时候,会在selector上注册标记位,标示可读、可写或者有连接到来。
注意,select是阻塞的,无论是通过操作系统的通知(epoll)还是不停的轮询(select,poll),这个函数是阻塞的。所以你可以放心大胆地在一个while(true)里面调用这个函数而不用担心CPU空转。
所以我们的程序大概的模样是:
1 | interface ChannelHandler{ |
这个程序很简短,也是最简单的Reactor模式:注册所有感兴趣的事件处理器,单线程轮询选择就绪事件,执行事件处理器。
优化线程模型
由上面的示例我们大概可以总结出NIO是怎么解决掉线程的瓶颈并处理海量连接的:
NIO由原来的阻塞读写(占用线程)变成了单线程轮询事件,找到可以进行读写的网络描述符进行读写。除了事件的轮询是阻塞的(没有可干的事情必须要阻塞),剩余的I/O操作都是纯CPU操作,没有必要开启多线程。
并且由于线程的节约,连接数大的时候因为线程切换带来的问题也随之解决,进而为处理海量连接提供了可能。
单线程处理I/O的效率确实非常高,没有线程切换,只是拼命的读、写、选择事件。但现在的服务器,一般都是多核处理器,如果能够利用多核心进行I/O,无疑对效率会有更大的提高。
仔细分析一下我们需要的线程,其实主要包括以下几种:
- 事件分发器,单线程选择就绪的事件。
- I/O处理器,包括connect、read、write等,这种纯CPU操作,一般开启CPU核心个线程就可以。
- 业务线程,在处理完I/O后,业务一般还会有自己的业务逻辑,有的还会有其他的阻塞I/O,如DB操作,RPC等。只要有阻塞,就需要单独的线程。
Java的Selector对于Linux系统来说,有一个致命限制:同一个channel的select不能被并发的调用。因此,如果有多个I/O线程,必须保证:一个socket只能属于一个IoThread,而一个IoThread可以管理多个socket。
另外连接的处理和读写的处理通常可以选择分开,这样对于海量连接的注册和读写就可以分发。虽然read()和write()是比较高效无阻塞的函数,但毕竟会占用CPU,如果面对更高的并发则无能为力。
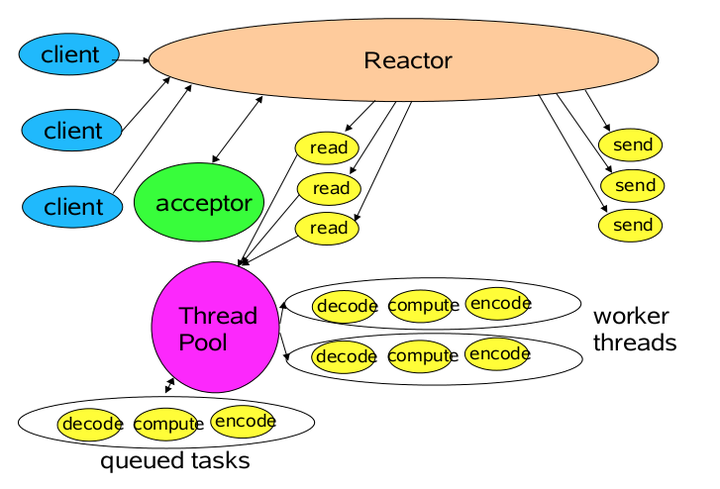
NIO在客户端的魔力
通过上面的分析,可以看出NIO在服务端对于解放线程,优化I/O和处理海量连接方面,确实有自己的用武之地。那么在客户端上,NIO又有什么使用场景呢?
常见的客户端BIO+连接池模型,可以建立n个连接,然后当某一个连接被I/O占用的时候,可以使用其他连接来提高性能。
但多线程的模型面临和服务端相同的问题:如果指望增加连接数来提高性能,则连接数又受制于线程数、线程很贵、无法建立很多线程,则性能遇到瓶颈。
每连接顺序请求的Redis
对于Redis来说,由于服务端是全局串行的,能够保证同一连接的所有请求与返回顺序一致。这样可以使用单线程+队列,把请求数据缓冲。然后pipeline发送,返回future,然后channel可读时,直接在队列中把future取回来,done()就可以了。
伪代码如下:
1 | class RedisClient Implements ChannelHandler{ |
这样做,能够充分的利用pipeline来提高I/O能力,同时获取异步处理能力。
多连接短连接的HttpClient
类似于竞对抓取的项目,往往需要建立无数的HTTP短连接,然后抓取,然后销毁,当需要单机抓取上千网站线程数又受制的时候,怎么保证性能呢?
何不尝试NIO,单线程进行连接、写、读操作?如果连接、读、写操作系统没有能力处理,简单的注册一个事件,等待下次循环就好了。
如何存储不同的请求/响应呢?由于http是无状态没有版本的协议,又没有办法使用队列,好像办法不多。比较笨的办法是对于不同的socket,直接存储socket的引用作为map的key。
常见的RPC框架,如Thrift,Dubbo
这种框架内部一般维护了请求的协议和请求号,可以维护一个以请求号为key,结果的result为future的map,结合NIO+长连接,获取非常不错的性能。
NIO高级主题
Proactor与Reactor
一般情况下,I/O 复用机制需要事件分发器(event dispatcher)。 事件分发器的作用,即将那些读写事件源分发给各读写事件的处理者,就像送快递的在楼下喊: 谁谁谁的快递到了, 快来拿吧!开发人员在开始的时候需要在分发器那里注册感兴趣的事件,并提供相应的处理者(event handler),或者是回调函数;事件分发器在适当的时候,会将请求的事件分发给这些handler或者回调函数。
涉及到事件分发器的两种模式称为:Reactor和Proactor。 Reactor模式是基于同步I/O的,而Proactor模式是和异步I/O相关的。在Reactor模式中,事件分发器等待某个事件或者可应用或个操作的状态发生(比如文件描述符可读写,或者是socket可读写),事件分发器就把这个事件传给事先注册的事件处理函数或者回调函数,由后者来做实际的读写操作。
而在Proactor模式中,事件处理者(或者代由事件分发器发起)直接发起一个异步读写操作(相当于请求),而实际的工作是由操作系统来完成的。发起时,需要提供的参数包括用于存放读到数据的缓存区、读的数据大小或用于存放外发数据的缓存区,以及这个请求完后的回调函数等信息。事件分发器得知了这个请求,它默默等待这个请求的完成,然后转发完成事件给相应的事件处理者或者回调。举例来说,在Windows上事件处理者投递了一个异步IO操作(称为overlapped技术),事件分发器等IO Complete事件完成。这种异步模式的典型实现是基于操作系统底层异步API的,所以我们可称之为“系统级别”的或者“真正意义上”的异步,因为具体的读写是由操作系统代劳的。
举个例子,将有助于理解Reactor与Proactor二者的差异,以读操作为例(写操作类似)。
在Reactor中实现读
- 注册读就绪事件和相应的事件处理器。
- 事件分发器等待事件。
- 事件到来,激活分发器,分发器调用事件对应的处理器。
- 事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
在Proactor中实现读:
- 处理器发起异步读操作(注意:操作系统必须支持异步IO)。在这种情况下,处理器无视IO就绪事件,它关注的是完成事件。
- 事件分发器等待操作完成事件。
- 在分发器等待过程中,操作系统利用并行的内核线程执行实际的读操作,并将结果数据存入用户自定义缓冲区,最后通知事件分发器读操作完成。
- 事件分发器呼唤处理器。
- 事件处理器处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分发器。
可以看出,两个模式的相同点,都是对某个I/O事件的事件通知(即告诉某个模块,这个I/O操作可以进行或已经完成)。在结构上,两者也有相同点:事件分发器负责提交IO操作(异步)、查询设备是否可操作(同步),然后当条件满足时,就回调handler;不同点在于,异步情况下(Proactor),当回调handler时,表示I/O操作已经完成;同步情况下(Reactor),回调handler时,表示I/O设备可以进行某个操作(can read 或 can write)。
下面,我们将尝试应对为Proactor和Reactor模式建立可移植框架的挑战。在改进方案中,我们将Reactor原来位于事件处理器内的Read/Write操作移至分发器(不妨将这个思路称为“模拟异步”),以此寻求将Reactor多路同步I/O转化为模拟异步I/O。以读操作为例子,改进过程如下:
- 注册读就绪事件和相应的事件处理器。并为分发器提供数据缓冲区地址,需要读取数据量等信息。
- 分发器等待事件(如在select()上等待)。
- 事件到来,激活分发器。分发器执行一个非阻塞读操作(它有完成这个操作所需的全部信息),最后调用对应处理器。
- 事件处理器处理用户自定义缓冲区的数据,注册新的事件(当然同样要给出数据缓冲区地址,需要读取的数据量等信息),最后将控制权返还分发器。
如我们所见,通过对多路I/O模式功能结构的改造,可将Reactor转化为Proactor模式。改造前后,模型实际完成的工作量没有增加,只不过参与者间对工作职责稍加调换。没有工作量的改变,自然不会造成性能的削弱。对如下各步骤的比较,可以证明工作量的恒定:
标准/典型的Reactor:
- 步骤1:等待事件到来(Reactor负责)。
- 步骤2:将读就绪事件分发给用户定义的处理器(Reactor负责)。
- 步骤3:读数据(用户处理器负责)。
- 步骤4:处理数据(用户处理器负责)。
改进实现的模拟Proactor:
步骤1:等待事件到来(Proactor负责)。
步骤2:得到读就绪事件,执行读数据(现在由Proactor负责)。
步骤3:将读完成事件分发给用户处理器(Proactor负责)。
步骤4:处理数据(用户处理器负责)。
对于不提供异步I/O API的操作系统来说,这种办法可以隐藏Socket API的交互细节,从而对外暴露一个完整的异步接口。借此,我们就可以进一步构建完全可移植的,平台无关的,有通用对外接口的解决方案。
代码示例如下:
1 | interface ChannelHandler{ |
Selector.wakeup()
主要作用
解除阻塞在Selector.select()/select(long)上的线程,立即返回。
两次成功的select之间多次调用wakeup等价于一次调用。
如果当前没有阻塞在select上,则本次wakeup调用将作用于下一次select——“记忆”作用。
为什么要唤醒?
注册了新的channel或者事件。
channel关闭,取消注册。
优先级更高的事件触发(如定时器事件),希望及时处理。
原理
Linux上利用pipe调用创建一个管道,Windows上则是一个loopback的tcp连接。这是因为win32的管道无法加入select的fd set,将管道或者TCP连接加入select fd set。
wakeup往管道或者连接写入一个字节,阻塞的select因为有I/O事件就绪,立即返回。可见,wakeup的调用开销不可忽视。
Buffer的选择
通常情况下,操作系统的一次写操作分为两步:
- 将数据从用户空间拷贝到系统空间。
- 从系统空间往网卡写。同理,读操作也分为两步:
① 将数据从网卡拷贝到系统空间;
② 将数据从系统空间拷贝到用户空间。
对于NIO来说,缓存的使用可以使用DirectByteBuffer和HeapByteBuffer。如果使用了DirectByteBuffer,一般来说可以减少一次系统空间到用户空间的拷贝。但Buffer创建和销毁的成本更高,更不宜维护,通常会用内存池来提高性能。
如果数据量比较小的中小应用情况下,可以考虑使用heapBuffer;反之可以用directBuffer。
NIO存在的问题
使用NIO != 高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。
NIO并没有完全屏蔽平台差异,它仍然是基于各个操作系统的I/O系统实现的,差异仍然存在。使用NIO做网络编程构建事件驱动模型并不容易,陷阱重重。
推荐大家使用成熟的NIO框架,如Netty,MINA等。解决了很多NIO的陷阱,并屏蔽了操作系统的差异,有较好的性能和编程模型。
总结
最后总结一下到底NIO给我们带来了些什么:
- 事件驱动模型
- 避免多线程
- 单线程处理多任务
- 非阻塞I/O,I/O读写不再阻塞,而是返回0
- 基于block的传输,通常比基于流的传输更高效
- 更高级的IO函数,zero-copy
- IO多路复用大大提高了Java网络应用的可伸缩性和实用性
2.1 反射的原理,反射创建类实例的三种方式是什么。
方法反射实例
1 | public class ReflectCase { |
通过Java的反射机制,可以在运行期间调用对象的任何方法,如果大量使用这种方式进行调用,会有性能或内存隐患么?为了彻底了解方法的反射机制,只能从底层代码入手了。
Method获取
调用Class类的getDeclaredMethod可以获取指定方法名和参数的方法对象Method。
getDeclaredMethod
1 |
|
其中privateGetDeclaredMethods方法从缓存或JVM中获取该Class中申明的方法列表,searchMethods方法将从返回的方法列表里找到一个匹配名称和参数的方法对象。
searchMethods
1 | private static Method searchMethods(Method[] methods, |
如果找到一个匹配的Method,则重新copy一份返回,即Method.copy()方法
1 | Method copy() { |
所次每次调用getDeclaredMethod方法返回的Method对象其实都是一个新的对象,且新对象的root属性都指向原来的Method对象,如果需要频繁调用,最好把Method对象缓存起来。
privateGetDeclaredMethods
从缓存或JVM中获取该Class中申明的方法列表,实现如下:
1 | private Method[] privateGetDeclaredMethods(boolean publicOnly) { |
其中reflectionData()方法实现如下:
1 | private ReflectionData<T> reflectionData() { |
这里有个比较重要的数据结构ReflectionData,用来缓存从JVM中读取类的如下属性数据:
1 | // reflection data that might get invalidated when JVM TI RedefineClasses() is called |
从reflectionData()方法实现可以看出:reflectionData对象是SoftReference类型的,说明在内存紧张时可能会被回收,不过也可以通过-XX:SoftRefLRUPolicyMSPerMB参数控制回收的时机,只要发生GC就会将其回收,如果reflectionData被回收之后,又执行了反射方法,那只能通过newReflectionData方法重新创建一个这样的对象了,newReflectionData方法实现如下:
1 | private ReflectionData<T> newReflectionData(SoftReference<ReflectionData<T>> oldReflectionData, |
通过unsafe.compareAndSwapObject方法重新设置reflectionData字段;
在privateGetDeclaredMethods方法中,如果通过reflectionData()获得的ReflectionData对象不为空,则尝试从ReflectionData对象中获取declaredMethods属性,如果是第一次,或则被GC回收之后,重新初始化后的类属性为空,则需要重新到JVM中获取一次,并赋值给ReflectionData,下次调用就可以使用缓存数据了。
Method调用
获取到指定的方法对象Method之后,就可以调用它的invoke方法了,invoke实现如下:
1 |
|
应该注意到:这里的MethodAccessor对象是invoke方法实现的关键,一开始methodAccessor为空,需要调用acquireMethodAccessor生成一个新的MethodAccessor对象,MethodAccessor本身就是一个接口,实现如下:
1 | public interface MethodAccessor { |
在acquireMethodAccessor方法中,会通过ReflectionFactory类的newMethodAccessor创建一个实现了MethodAccessor接口的对象,实现如下:
1 | public MethodAccessor newMethodAccessor(Method var1) { |
在ReflectionFactory类中,有2个重要的字段:noInflation(默认false)和inflationThreshold(默认15),在checkInitted方法中可以通过-Dsun.reflect.inflationThreshold=xxx和-Dsun.reflect.noInflation=true对这两个字段重新设置,而且只会设置一次;
如果noInflation为false,方法newMethodAccessor都会返回DelegatingMethodAccessorImpl对象,DelegatingMethodAccessorImpl的类实现
1 | class DelegatingMethodAccessorImpl extends MethodAccessorImpl { |
其实,DelegatingMethodAccessorImpl对象就是一个代理对象,负责调用被代理对象delegate的invoke方法,其中delegate参数目前是NativeMethodAccessorImpl对象,所以最终Method的invoke方法调用的是NativeMethodAccessorImpl对象invoke方法,实现如下:
1 | public Object invoke(Object var1, Object[] var2) throws IllegalArgumentException, InvocationTargetException { |
这里用到了ReflectionFactory类中的inflationThreshold,当delegate调用了15次invoke方法之后,如果继续调用就通过MethodAccessorGenerator类的generateMethod方法生成MethodAccessorImpl对象,并设置为delegate对象,这样下次执行Method.invoke时,就调用新建的MethodAccessor对象的invoke()方法了。
这里需要注意的是:
generateMethod方法在生成MethodAccessorImpl对象时,会在内存中生成对应的字节码,并调用ClassDefiner.defineClass创建对应的class对象,实现如下:
1 | return (MagicAccessorImpl)AccessController.doPrivileged(new PrivilegedAction<MagicAccessorImpl>() { |
在ClassDefiner.defineClass方法实现中,每被调用一次都会生成一个DelegatingClassLoader类加载器对象
1 | static Class<?> defineClass(String var0, byte[] var1, int var2, int var3, final ClassLoader var4) { |
这里每次都生成新的类加载器,是为了性能考虑,在某些情况下可以卸载这些生成的类,因为类的卸载是只有在类加载器可以被回收的情况下才会被回收的,如果用了原来的类加载器,那可能导致这些新创建的类一直无法被卸载,从其设计来看本身就不希望这些类一直存在内存里的,在需要的时候有就行了。
获取class
Class 类的实例表示正在运行的 Java 应用程序中的类和接口。获取类的Class对象有多种方式:
- 调用getClass
1 | Boolean var1 = true; |
- 运用.class 语法
1 | Class<?> classType4 = Boolean.class; |
- 运用static method Class.forName()
1 | Class<?> classType5 = Class.forName("java.lang.Boolean"); |
- 运用primitive wrapper classes的TYPE 语法
1 | 这里返回的是原生类型,和Boolean.class返回的不同 |
实例化类对象
- 通过 Class 对象的 newInstance() 方法。
1 | Class clz = Person.class; |
- 通过 Constructor 对象的 newInstance() 方法
1 | Class clz = Person.class; |
通过 Constructor 对象创建类对象可以选择特定构造方法,而通过 Class 对象则只能使用默认的无参数构造方法。下面的代码就调用了一个有参数的构造方法进行了类对象的初始化。
1 | Class clz = Person.class; |
2.2 反射中,Class.forName和ClassLoader区别 。
ClassLoader.loadClass()与Class.forName()大家都知道是反射用来构造类的方法,但是他们的用法还是有一定区别的。
在讲区别之前,我觉得很有不要把类的加载过程在此整理一下。
在Java中,类装载器把一个类装入Java虚拟机中,要经过三个步骤来完成:装载、链接和初始化,其中链接又可以分成校验、准备和解析三步,除了解析外,其它步骤是严格按照顺序完成的,各个步骤的主要工作如下:
装载:查找和导入类或接口的二进制数据;
链接:执行下面的校验、准备和解析步骤,其中解析步骤是可以选择的;
校验:检查导入类或接口的二进制数据的正确性;
准备:给类的静态变量分配并初始化存储空间;
解析:将符号引用转成直接引用;
初始化:激活类的静态变量的初始化Java代码和静态Java代码块。
于是乎我们可以开始看2者的区别了。
Class.forName(className)方法,其实调用的方法是Class.forName(className,true,classloader);注意看第2个boolean参数,它表示的意思,在loadClass后必须初始化。比较下jvm加载类的知识,我们可以清晰的看到在执行过此方法后,目标对象的 static块代码已经被执行,static参数也已经被初始化。
再看ClassLoader.loadClass(className)方法,其实他调用的方法是ClassLoader.loadClass(className,false);还是注意看第2个 boolean参数,该参数表示目标对象被装载后不进行链接,这就意味这不会去执行该类静态块中间的内容。因此2者的区别就显而易见了。
最后还有必要在此提一下new方法和newInstance方法的区别
newInstance: 弱类型。低效率。只能调用无参构造。
new: 强类型。相对高效。能调用任何public构造。
例如,在JDBC编程中,常看到这样的用法,Class.forName(“com.mysql.jdbc.Driver”),如果换成了 getClass().getClassLoader().loadClass(“com.mysql.jdbc.Driver”),就不行。
为什么呢?打开com.mysql.jdbc.Driver的源代码看看,
1 | // |
Driver在static块中会注册自己到java.sql.DriverManager。而static块就是在Class的初始化中被执行。所以这个地方就只能用Class.forName(className)。
2.3 描述动态代理的几种实现方式,分别说出相应的优缺点。
代理可以分为 “静态代理” 和 “动态代理”,动态代理又分为 “JDK动态代理” 和 “CGLIB动态代理” 实现。
静态代理:代理对象和实际对象都继承了同一个接口,在代理对象中指向的是实际对象的实例,这样对外暴露的是代理对象而真正调用的是 Real Object
- 优点:可以很好的保护实际对象的业务逻辑对外暴露,从而提高安全性。
- 缺点:不同的接口要有不同的代理类实现,会很冗余
JDK 动态代理:
- 为了解决静态代理中,生成大量的代理类造成的冗余;
- JDK 动态代理只需要实现 InvocationHandler 接口,重写 invoke 方法便可以完成代理的实现,
- jdk的代理是利用反射生成代理类 Proxyxx.class 代理类字节码,并生成对象
- jdk动态代理之所以只能代理接口是因为代理类本身已经extends了Proxy,而java是不允许多重继承的,但是允许实现多个接口
- 优点:解决了静态代理中冗余的代理实现类问题。
- 缺点:JDK 动态代理是基于接口设计实现的,如果没有接口,会抛异常。
CGLIB 代理:
- 由于 JDK 动态代理限制了只能基于接口设计,而对于没有接口的情况,JDK方式解决不了;
- CGLib 采用了非常底层的字节码技术,其原理是通过字节码技术为一个类创建子类,并在子类中采用方法拦截的技术拦截所有父类方法的调用,顺势织入横切逻辑,来完成动态代理的实现。
- 实现方式实现 MethodInterceptor 接口,重写 intercept 方法,通过 Enhancer 类的回调方法来实现。
- 但是CGLib在创建代理对象时所花费的时间却比JDK多得多,所以对于单例的对象,因为无需频繁创建对象,用CGLib合适,反之,使用JDK方式要更为合适一些。
- 同时,由于CGLib由于是采用动态创建子类的方法,对于final方法,无法进行代理。
- 优点:没有接口也能实现动态代理,而且采用字节码增强技术,性能也不错。
- 缺点:技术实现相对难理解些。
2.4 动态代理与cglib实现的区别。
JDK动态代理与CGLIB动态代理对比
JDK动态代理:基于Java反射机制实现,必须要实现了接口的业务类才能用这种办法生成代理对象。
cglib动态代理:基于ASM机制实现,通过生成业务类的子类作为代理类。
JDK Proxy 的优势:
- 最小化依赖关系,减少依赖意味着简化开发和维护,JDK 本身的支持,可能比 cglib 更加可靠。
- 平滑进行 JDK 版本升级,而字节码类库通常需要进行更新以保证在新版 Java 上能够使用。
- 代码实现简单。
基于类似 cglib 框架的优势:
- 无需实现接口,达到代理类无侵入
- 只操作我们关心的类,而不必为其他相关类增加工作量。
- 高性能
2.5 为什么CGlib方式可以对接口实现代理。
参考2.3
1 | import net.sf.cglib.proxy.Enhancer; |
2.6 final的用途。
Java中final修饰符既可以修饰类、方法,也可以修饰变量.
基本规则
- 用final修饰的类不能被扩展,也就是说不可能有子类;
- 用final修饰的方法不能被替换或隐藏:
- 使用final修饰的实例方法在其所属类的子类中不能被替换(overridden);
- 使用final修饰的静态方法在其所属类的子类中不能被重定义(redefined)而隐藏(hidden);
- 用final修饰的变量最多只能赋值一次,在赋值方式上不同类型的变量或稍有不同:
- 静态变量必须明确赋值一次(不能只使用类型缺省值);作为类成员的静态变量,赋值可以在其声明中通过初始化表达式完成,也可以在静态初始化块中进行;作为接口成员的静态变量,赋值只能在其声明中通过初始化表达式完成;
- 实例变量同样必须明确赋值一次(不能只使用类型缺省值);赋值可以在其声明中通过初始化表达式完成,也可以在实例初始化块或构造器中进行;
- 方法参数变量在方法被调用时创建,同时被初始化为对应实参值,终止于方法体(body)结束,在此期间其值不能改变;
- 构造器参数变量在构造器被调用(通过实例创建表达式或显示的构造器调用)时创建,同时被初始化为对应实参值,终止于构造器体结束,在此期间其值不能改变;
- 异常处理器参数变量在有异常被try语句的catch子句捕捉到时创建,同时被初始化为实际的异常对象,终止于catch语句块结束,在此期间其值不能改变;
- 局部变量在其值被访问之前必须被明确赋值;
关于final变量的进一步说明:
- 定义:blank final变量是其声明中不包含初始化表达式的final变量。
- 对于引用类型变量,final修饰符表示一旦赋值该变量就始终指向堆中同一个对象,不可改变,但是其所指对象本身(其状态)是可以改变的;不象C++中的const,在Java中没有办法仅通过一个final就可声明一个对象的不变性(immutability)。
- 常变量(constant variable):
- 定义:常变量是用编译时常量表达式初始化的带有final修饰符的基本类型或字符串类型变量;
- 无论静态变量还是实例变量,如果它是常变量,则其引用在编译时会被解析成该常变量所表示的值,在class文件中并不存在任何对常变量域的引用;也正是基于此,当在源代码中修改某个常变量域的初始值并重新编译后,该改动并不为其他class文件可见,除非对他们也重新编译。
final变量的初始化
共性:
- final在初始化之后,就不能再赋值了,也就是说,它们只能被赋值一次
- 一般情况下是定义时直接初始化如:
1
final int i=3;
但也可以定义时不初始化,叫blank final,如:
1
final int bi;
然后留待后面进行赋值。
但这因三种情况而不同:
1.普通auto变量(就是如方法中的局部变量):可以在其后的代码中赋值,但也可以不赋值。
1
2
3
4final int i;//blank final
anything();
i=1;//在其后赋值。
i=3; //error!不可再次赋值而成员变量必须被赋值,只是赋值的地方不同:
- 静态成员变量:
静态成员变量必须在静态构造代码中初始化,
1
2static final int s;
static { s=3;}//静态构造块- 非静态成员变量:
必须在构造函数中被赋值。如:
1
2
3
4final int ai;
{ ai = 3; }//instance initializer
public Contructor(){ai=3;}//构造函数中
public Contructor(int in){ai=in;}//构造函数中注意构造函数可以会有互相调用,注意在这过程中不要使变量被重复的赋值。
另外,如果变量是对象或数组这样的引用类型。则可以操作其对象或数组,但不可以改变引用本身:
1
2
3final int [] array={1,2,3};//一个由三个数字组成的数组。
array[1]=9;//array == {1,9,3}
// array=new int[6]; error!
2.7 写出三种单例模式实现 。
单例模式的定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点!
懒汉,线程不安全
1
2
3
4
5
6
7
8
9
10
11public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}这种写法能够在多线程中很好的工作,而且看起来它也具备很好的lazy loading,但是,遗憾的是,效率很低,99%情况下不需要同步。
饿汉
1
2
3
4
5
6
7public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}这种方式基于classloder机制避免了多线程的同步问题,instance在类装载时就实例化。目前java单例是指一个虚拟机的范围,因为装载类的功能是虚拟机的,所以一个虚拟机在通过自己的ClassLoader装载饿汉式实现单例类的时候就会创建一个类的实例。这就意味着一个虚拟机里面有很多ClassLoader,而这些classloader都能装载某个类的话,就算这个类是单例,也能产生很多实例。当然如果一台机器上有很多虚拟机,那么每个虚拟机中都有至少一个这个类的实例的话,那这样 就更不会是单例了。(这里讨论的单例不适合集群!)
静态内部类
1
2
3
4
5
6
7
8
9public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
这种方式同样利用了classloder的机制来保证初始化instance时只有一个线程,这种方式是Singleton类被装载了,instance不一定被初始化。因为SingletonHolder类没有被主动使用,只有显示通过调用getInstance方法时,才会显示装载SingletonHolder类,从而实例化instance。想象一下,如果实例化instance很消耗资源,我想让他延迟加载!这个时候,这种方式相比第2种方式就显得很合理。
4.枚举
1 | public enum Singleton { |
这种方式是Effective Java作者Josh Bloch 提倡的方式,它不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象,可谓是很坚强的壁垒啊,不过,个人认为由于1.5中才加入enum特性,用这种方式写不免让人感觉生疏,在实际工作中,我也很少看见有人这么写过。
5.双重校验锁(jdk1.5)
1 | public class Singleton { |
这样方式实现线程安全地创建实例,而又不会对性能造成太大影响。它只是第一次创建实例的时候同步,以后就不需要同步了。
由于volatile关键字屏蔽了虚拟机中一些必要的代码优化,所以运行效率并不是很高,因此建议没有特别的需要不要使用。双重检验锁方式的单例不建议大量使用,根据情况决定。
总结
有两个问题需要注意:
1.如果单例由不同的类装载器装入,那便有可能存在多个单例类的实例。假定不是远端存取,例如一些servlet容器对每个servlet使用完全不同的类装载器,这样的话如果有两个servlet访问一个单例类,它们就都会有各自的实例。
2.如果Singleton实现了java.io.Serializable接口,那么这个类的实例就可能被序列化和复原。不管怎样,如果你序列化一个单例类的对象,接下来复原多个那个对象,那你就会有多个单例类的实例。
对第一个问题修复的办法是:
1 | private static Class getClass(String classname) |
对第二个问题修复的办法是:
1 | public class Singleton implements java.io.Serializable { |
2.8 如何在父类中为子类自动完成所有的hashcode和equals实现?这么做有何优劣。
覆盖equals时需要遵守的通用约定:
覆盖equals方法看起来似乎很简单,但是如果覆盖不当会导致错误,并且后果相当严重。《Effective Java》一书中提到“最容易避免这类问题的办法就是不覆盖equals方法”,这句话貌似很搞笑,其实想想也不无道理,其实在这种情况下,类的每个实例都只与它自身相等。如果满足了以下任何一个条件,这就正是所期望的结果:
- 类的每个实例本质上都是唯一的。对于代表活动实体而不是值的类来说却是如此,例如Thread。Object提供的equals实现对于这些类来说正是正确的行为。
- 不关心类是否提供了“逻辑相等”的测试功能。假如Random覆盖了equals,以检查两个Random实例是否产生相同的随机数序列,但是设计者并不认为客户需要或者期望这样的功能。在这样的情况下,从Object继承得到的equals实现已经足够了。
- 超类已经覆盖了equals,从超类继承过来的行为对于子类也是合适的。大多数的Set实现都从AbstractSet继承equals实现,List实现从AbstractList继承equals实现,Map实现从AbstractMap继承equals实现。
- 类是私有的或者是包级私有的,可以确定它的equals方法永远不会被调用。在这种情况下,无疑是应该覆盖equals方法的,以防止它被意外调用:
1 |
|
在覆盖equals方法的时候,你必须要遵守它的通用约定。下面是约定的内容,来自Object的规范[JavaSE6]
自反性。对于任何非null的引用值x,x.equals(x)必须返回true。
对称性。对于任何非null的引用值x和y,当且仅当y.equals(x)返回true时,x.equals(y)必须返回true
- 传递性。对于任何非null的引用值x、y和z,如果x.equals(y)返回true,并且y.equals(z)也返回true,那么x.equals(z)也必须返回true。
- 一致性。对于任何非null的引用值x和y,只要equals的比较操作在对象中所用的信息没有被修改,多次调用该x.equals(y)就会一直地返回true,或者一致地返回false。
- 对于任何非null的引用值x,x.equals(null)必须返回false。
结合以上要求,得出了以下实现高质量equals方法的诀窍:
使用==符号检查“参数是否为这个对象的引用”。如果是,则返回true。这只不过是一种性能优化,如果比较操作有可能很昂贵,就值得这么做。
使用instanceof操作符检查“参数是否为正确的类型”。如果不是,则返回false。一般来说,所谓“正确的类型”是指equals方法所在的那个类。
- 把参数转换成正确的类型。因为转换之前进行过instanceof测试,所以确保会成功。
- 对于该类中的每个“关键”域,检查参数中的域是否与该对象中对应的域相匹配。如果这些测试全部成功,则返回true;否则返回false。
- 当编写完成了equals方法之后,检查“对称性”、“传递性”、“一致性”。
注意:
- 覆盖equals时总要覆盖hashCode 《Effective Java》作者说的
- 不要企图让equals方法过于只能。
- 不要将equals声明中的Object对象替换为其他的类型(因为这样我们并没有覆盖Object中的equals方法哦)
覆盖equals时总要覆盖hashCode
一个很常见的错误根源在于没有覆盖hashCode方法。在每个覆盖了equals方法的类中,也必须覆盖hashCode方法。如果不这样做的话,就会违反Object.hashCode的通用约定,从而导致该类无法结合所有基于散列的集合一起正常运作,这样的集合包括HashMap、HashSet和Hashtable。
- 在应用程序的执行期间,只要对象的equals方法的比较操作所用到的信息没有被修改,那么对这同一个对象调用多次,hashCode方法都必须始终如一地返回同一个整数。在同一个应用程序的多次执行过程中,每次执行所返回的整数可以不一致。
- 如果两个对象根据equals()方法比较是相等的,那么调用这两个对象中任意一个对象的hashCode方法都必须产生同样的整数结果。
- 如果两个对象根据equals()方法比较是不相等的,那么调用这两个对象中任意一个对象的hashCode方法,则不一定要产生相同的整数结果。但是程序员应该知道,给不相等的对象产生截然不同的整数结果,有可能提高散列表的性能。
2.9 请结合OO设计理念,谈谈访问修饰符public、private、protected、default在应用设计中的作用。
访问修饰符,主要标示修饰块的作用域,方便隔离防护
作用域 类内部 同包 子类 其他包
public √ √ √ √
protected √ √ √ ×
friendly √ √ × ×
private √ × × ×
public: Java语言中访问限制最宽的修饰符,一般称之为“公共的”。被其修饰的类、属性以及方法不
仅可以跨类访问,而且允许跨包(package)访问。
private: Java语言中对访问权限限制的最窄的修饰符,一般称之为“私有的”。被其修饰的类、属性以
及方法只能被该类的对象访问,其子类不能访问,更不能允许跨包访问。
protect: 介于public 和 private 之间的一种访问修饰符,一般称之为“保护形”。被其修饰的类、
属性以及方法只能被类本身的方法及子类访问,即使子类在不同的包中也可以访问。
default:即不加任何访问修饰符,通常称为“默认访问模式“。该模式下,只允许在同一个包中进行访
问。
3.0 深拷贝和浅拷贝区别。
什么是拷贝?
开始之前,我要先强调一下 Java 中的拷贝是什么。首先,让我们对引用拷贝和对象拷贝进行一下区分。
引用拷贝, 正如它的名称所表述的意思, 就是创建一个指向对象的引用变量的拷贝。如果我们有一个 Car 对象,而且让 myCar 变量指向这个变量,这时候当我们做引用拷贝,那么现在就会有两个 myCar 变量,但是对象仍然只存在一个。

对象拷贝会创建对象本身的一个副本。因此如果我们再一次服务我们 car 对象,就会创建这个对象本身的一个副本, 同时还会有第二个引用变量指向这个被复制出来的对象。

什么是对象?
深拷贝和浅拷贝都是对象拷贝, 但一个对象实际是什么呢? 当我们谈论到对象时,我们经常会说它就像一粒浑圆的咖啡豆,已经是一个不能够被进一步分解的单位了,但这种说法太过于简化了。

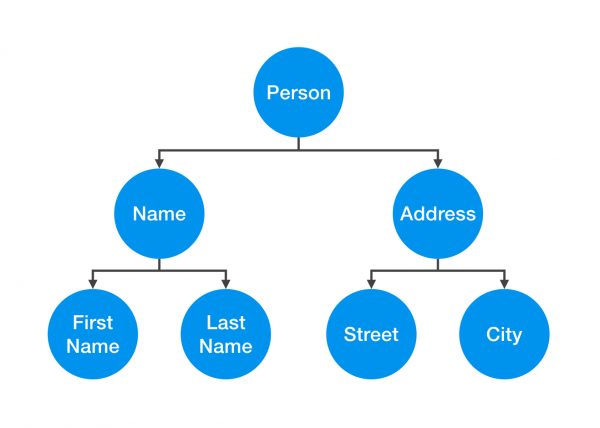
比方说我们有一个 Person 对象。这个 Person 对象实际上是由其它的对象组合而成的。如下图所示, Person 对象包含了一个 Name 对象和一个 Address 对象。Name 对象又包含了一个 FirstName 对象和一个 LastName 对象;Address 对象又是由一个 Street 对象以及一个 City 对象组合而成的。那么当我们讨论本文中的这个 Person 时,实际上我是在讨论这些个对象所组成的整个的对象联系网络。
那么为什么我会要对这个 Person 对象进行拷贝呢? 对象复制,经常也会被称作克隆,它是在我们想要修改或者移除某个对象,但仍然想要保留原来的那个对象时所要进行的操作。
浅拷贝
首先让我们来说说浅拷贝。对象的浅拷贝会对“主”对象进行拷贝,但不会复制主对象里面的对象。”里面的对象“会在原来的对象和它的副本之间共享。例如,我们会为一个 Person对象创建第二个 Person 对象, 而两个 Person 会共享相同的 Name 和 Address 对象。
让我们来看看代码示例。如中,我们有一个类 Person,类里面包含了一个 Name 和 Address 对象。拷贝构造器会拿到 originalPerson 对象,然后对其应用变量进行复制。
1 | public class Person { |
浅拷贝的问题就是两个对象并非独立的。如果你修改了其中一个 Person 对象的 Name 对象,那么这次修改也会影响奥另外一个 Person 对象。
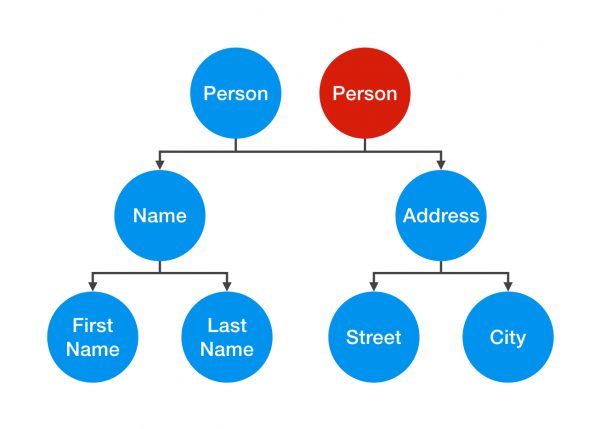
让我们在示例中看看这个问题。假如说我们有一个 Person 对象,然后也会有一个引用变量 monther 来指向它;然后当我们对 mother 进行拷贝时,创建第二个 Person 对象 son。如果在此后的代码中, son 尝试用 moveOut() 来修改他的 Address 对象, 那么 mother 也会跟着他一起搬走!
1 | Person mother = new Person(new Name(…), new Address(…)); |
这种现象之所以会发生,是因为 mother 和son 对象共享了相同的 Address 对象,如你在示例 7 中所看到的描述。当我们在一个对象中修改了 Address 对象,那么也就表示两个对象总的 Address 都被修改了。
深拷贝
不同于浅拷贝,深拷贝是一个整个独立的对象拷贝。如果我们对整个 Person对象进行深拷贝,我们会对整个对象的结构都进行拷贝。

如你在上图中所见,对一个 Person 的Address对象进行了修改并不会对另外一个对象造成影响。当我们观察示下面的代码,会发现我们不单单对 Person 对象使用了拷贝构造器,同时也会对里面的对象使用拷贝构造器。
1 | public class Person { |
使用这种深拷贝,我们可以重新尝试示上面的 mother-son 这个用例。现在 son 可以成功的搬走了!
不过,故事到这儿并没有结束。要创建一个真正的深拷贝,就需要我们一直这样拷贝下去,一直覆盖到 Person 对象所有的内部元素, 最后只剩下原始的类型以及“不可变对象(Immutables)”。让我们观察下如下这个 Street 类以获得更好的理解:
1 | public class Street { |
Street 对象有两个实体变量组成 – String 类型的 name 以及 int 类型的 number。int 类型的 number 是一个原始类型,并非对象。它只是一个简单的值,不能共享, 因此在创建第二个实体变量时,我们可以自动创建一个独立的拷贝。String 是一个不可变对象(Immutable)。简言之,不可变对象也是对象,可一旦创建好了以后就再也不能被修改了。因此,你可以不用为其创建深拷贝就能对其进行共享。
总结
作为总结,我要说说上面在 mother-son 示例中所用到的一些编码技术。只是因为深拷贝可以让你修改一个对象里面的详细信息,比如 Address 对象,这并不意味着你就该这样做。这样做会提高代码的质量, 因为它可以使得 Person 更容易修改 – 不管 Address 类什么时候被修改了,你也都会要修改应用到 Person 类。例如,如果 Address 类型不再包含 Street 对象了,我们就得根据已经对 Address 类做出的修改来对Person 类中的 moveOut() 方法进行修改。
在本文中,我只选择使用了一个新的 Street 和 City 对象,这样可以更好的对浅拷贝和深拷贝的不同之处进行描述。不过,我会建议你给方法分配一个新的 Address 对象,这样能有效的将其转换成一个浅拷贝和深拷贝的混合体:
1 | Person mother = new Person(new Name(…), new Address(…)); |
在面向对象领域,这样做违背了封装的原则,因此应该被避免。封装是面向对象编程中一个最重要的方面。在这里,我已经违背封装的原则,对 Person 类中 Address 对象的内部细节进行了访问。这样做对我们的代码造成了伤害,因为我们现在跟 Person 类中的 Address 类纠缠在一起,如果对 Address 类进行了修改,就会如我上面所解释的对代码造成伤害。不过是你显然是会需要将你定义的各种类互相联系在一起以构成代码工程的,但在你要将两个类联系在一起时,需要好好分析一下成本和收益。
3.1 数组和链表数据结构描述,各自的时间复杂度。
概述
数组
是将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。但是如果要在数组中增加一个元素,需要移动大量元素,在内存中空出一个元素的空间,然后将要增加的元素放在其中。同样的道理,如果想删除一个元素,同样需要移动大量元素去填掉被移动的元素。如果应用需要快速访问数据,很少插入和删除元素,就应该用数组。
链表
元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起,每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的 指针。
如果要访问链表中一个元素,需要从第一个元素开始,一直找到需要的元素位置。但是增加和删除一个元素对于链表数据结构就非常简单了,只要修改元素中的指针就可以了。如果应用需要经常插入和删除元素你就需要用链表。
内存存储区别
数组从栈中分配空间, 对于程序员方便快速,但自由度小。
链表从堆中分配空间, 自由度大但申请管理比较麻烦.
逻辑结构区别
数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费。
链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项)
总结
1、存取方式上,数组可以顺序存取或者随机存取,而链表只能顺序存取;
2、存储位置上,数组逻辑上相邻的元素在物理存储位置上也相邻,而链表不一定;
3、存储空间上,链表由于带有指针域,存储密度不如数组大;
4、按序号查找时,数组可以随机访问,时间复杂度为O(1),而链表不支持随机访问,平均需要O(n);
5、按值查找时,若数组无序,数组和链表时间复杂度均为O(n),但是当数组有序时,可以采用二分查找将时间复杂度降为O(logn);
6、插入和删除时,数组平均需要移动n/2个元素,而链表只需修改指针即可;
7、空间分配方面:
数组在静态存储分配情形下,存储元素数量受限制,动态存储分配情形下,虽然存储空间可以扩充,但需要移 动大量元素,导致操作效率降低,而且如果内存中没有更大块连续存储空间将导致分配失败;
链表存储的节点空间只在需要的时候申请分配,只要内存中有空间就可以分配,操作比较灵活高效;
3.2 error和exception的区别,CheckedException,RuntimeException的区别。
Exception
一般分为Checked异常和Runtime异常,所有RuntimeException类及其子类的实例被称为Runtime异常,不属于该范畴的异常则被称为CheckedException。
Checked异常
只有java语言提供了Checked异常,Java认为Checked异常都是可以被处理的异常,所以Java程序必须显示处理Checked异常。如果程序没有处理Checked异常,该程序在编译时就会发生错误无法编译。这体现了Java的设计哲学:没有完善错误处理的代码根本没有机会被执行。对Checked异常处理方法有两种
1 当前方法知道如何处理该异常,则用try…catch块来处理该异常。
2 当前方法不知道如何处理,则在定义该方法是声明抛出该异常。
我们比较熟悉的Checked异常有
Java.lang.ClassNotFoundException
Java.lang.NoSuchMetodException
java.io.IOException
RuntimeException
Runtime如除数是0和数组下标越界等,其产生频繁,处理麻烦,若显示申明或者捕获将会对程序的可读性和运行效率影响很大。所以由系统自动检测并将它们交给缺省的异常处理程序。当然如果你有处理要求也可以显示捕获它们。
我们比较熟悉的RumtimeException子类:
Java.lang.ArithmeticException
Java.lang.ArrayStoreExcetpion
Java.lang.ClassCastException
Java.lang.IndexOutOfBoundsException
Java.lang.NullPointerException
Error
当程序发生不可控的错误时,通常做法是通知用户并中止程序的执行。与异常不同的是Error及其子类的对象不应被抛出。
Error是throwable的子类,代表编译时间和系统错误,用于指示合理的应用程序不应该试图捕获的严重问题。
Error由Java虚拟机生成并抛出,包括动态链接失败,虚拟机错误等。程序对其不做处理。
3.3 请列出5个运行时异常。
Java.lang.ArithmeticException
Java.lang.ArrayStoreExcetpion
Java.lang.ClassCastException
Java.lang.IndexOutOfBoundsException
Java.lang.NullPointerException
3.4 在自己的代码中,如果创建一个java.lang.String类,这个类是否可以被类加载器加载?为什么。
双亲委派模型
类加载器可分为两类:一是启动类加载器(Bootstrap ClassLoader),是C++实现的,是JVM的一部分;另一种是其它的类加载器,是Java实现的,独立于JVM,全部都继承自抽象类java.lang.ClassLoader。jdk自带了三种类加载器,分别是启动类加载器(Bootstrap ClassLoader),扩展类加载器(Extension ClassLoader),应用程序类加载器(Application ClassLoader)。后两种加载器是继承自抽象类java.lang.ClassLoader。
一般是: 自定义类加载器 >> 应用程序类加载器 >> 扩展类加载器 >> 启动类加载器
上面的层次关系被称为双亲委派模型(Parents Delegation Model)。除了最顶层的启动类加载器外,其余的类加载器都有对应的父类加载器。
简单说下双亲委托机制:如果一个类加载器收到了类加载的请求,它首先不会自己尝试去加载这个类,而是把这个请求委派给父类加载器,每一个层次的类加载器都是加此,因此所有的加载请求最终到达顶层的启动类加载器,只有当父类加载器反馈自己无法完成加载请求时(指它的搜索范围没有找到所需的类),子类加载器才会尝试自己去加载。
各个类加载器之间是组合关系,并非继承关系。
双亲委派模型可以确保安全性,可以保证所有的Java类库都是由启动类加载器加载。如用户编写的java.lang.Object,加载请求传递到启动类加载器,启动类加载的是系统中的Object对象,而用户编写的java.lang.Object不会被加载。如用户编写的java.lang.virus类,加载请求传递到启动类加载器,启动类加载器发现virus类并不是核心Java类,无法进行加载,将会由具体的子类加载器进行加载,而经过不同加载器进行加载的类是无法访问彼此的。由不同加载器加载的类处于不同的运行时包。所有的访问权限都是基于同一个运行时包而言的。
为什么要使用这种双亲委托模式呢?
因为这样可以避免重复加载,当父亲已经加载了该类的时候,就没有必要子ClassLoader再加载一次。
考虑到安全因素,我们试想一下,如果不使用这种委托模式,那我们就可以随时使用自定义的String来动态替代java核心api中定义类型,这样会存在非常大的安全隐患,而双亲委托的方式,就可以避免这种情况,因为String已经在启动时被加载,所以用户自定义类是无法加载一个自定义的ClassLoader。
思考:假如我们自己写了一个java.lang.String的类,我们是否可以替换调JDK本身的类?
答案是否定的。我们不能实现。为什么呢?我看很多网上解释是说双亲委托机制解决这个问题,其实不是非常的准确。因为双亲委托机制是可以打破的,你完全可以自己写一个classLoader来加载自己写的java.lang.String类,但是你会发现也不会加载成功,具体就是因为针对java.*开头的类,jvm的实现中已经保证了必须由bootstrp来加载。
因加载某个类时,优先使用父类加载器加载需要使用的类。如果我们自定义了java.lang.String这个类, 加载该自定义的String类,该自定义String类使用的加载器是AppClassLoader,根据优先使用父类加载器原理, AppClassLoader加载器的父类为ExtClassLoader,所以这时加载String使用的类加载器是ExtClassLoader, 但是类加载器ExtClassLoader在jre/lib/ext目录下没有找到String.class类。然后使用ExtClassLoader父类的加载器BootStrap, 父类加载器BootStrap在JRE/lib目录的rt.jar找到了String.class,将其加载到内存中。这就是类加载器的委托机制。
定义自已的ClassLoader
既然JVM已经提供了默认的类加载器,为什么还要定义自已的类加载器呢?
因为Java中提供的默认ClassLoader,只加载指定目录下的jar和class,如果我们想加载其它位置的类或jar时,比如:我要加载网络上的一个class文件,通过动态加载到内存之后,要调用这个类中的方法实现我的业务逻辑。在这样的情况下,默认的ClassLoader就不能满足我们的需求了,所以需要定义自己的ClassLoader。
定义自已的类加载器分为两步:
1、继承java.lang.ClassLoader
2、重写父类的findClass方法
可能在这里有疑问,父类有那么多方法,为什么偏偏只重写findClass方法?
因为JDK已经在loadClass方法中帮我们实现了ClassLoader搜索类的算法,当在loadClass方法中搜索不到类时,loadClass方法就会调用findClass方法来搜索类,所以我们只需重写该方法即可。如没有特殊的要求,一般不建议重写loadClass搜索类的算法。
3.5 说一说你对java.lang.Object对象中hashCode和equals方法的理解。在什么场景下需要重新实现这两个方法。
hashcode
hashcode()方法提供了对象的hashCode值,是一个native方法,返回的默认值与System.identityHashCode(obj)一致。
通常这个值是对象头部的一部分二进制位组成的数字,具有一定的标识对象的意义存在,但绝不定于地址。
作用是:用一个数字来标识对象。比如在HashMap、HashSet等类似的集合类中,如果用某个对象本身作为Key,即要基于这个对象实现Hash的写入和查找,那么对象本身如何实现这个呢?就是基于hashcode这样一个数字来完成的,只有数字才能完成计算和对比操作。
hashcode是否唯一
hashcode只能说是标识对象,在hash算法中可以将对象相对离散开,这样就可以在查找数据的时候根据这个key快速缩小数据的范围,但hashcode不一定是唯一的,所以hash算法中定位到具体的链表后,需要循环链表,然后通过equals方法来对比Key是否是一样的。
equals与hashcode的关系
equals相等两个对象,则hashcode一定要相等。但是hashcode相等的两个对象不一定equals相等。
小结
hashcode是为了算法快速定位数据而存在的,而equals是为了对比真实值而存在的。
3.6 在jdk1.5中,引入了泛型,泛型的存在是用来解决什么问题。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数,泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,以提高代码的重用率。
第一是泛化。可以用T代表任意类型Java语言中引入泛型是一个较大的功能增强不仅语言、类型系统和编译器有了较大的变化,以支持泛型,而且类库也进行了大翻修,所以许多重要的类,比如集合框架,都已经成为泛型化的了,这带来了很多好处。
第二是类型安全。泛型的一个主要目标就是提高ava程序的类型安全,使用泛型可以使编译器知道变量的类型限制,进而可以在更高程度上验证类型假设。如果不用泛型,则必须使用强制类型转换,而强制类型转换不安全,在运行期可能发生ClassCast Exception异常,如果使用泛型,则会在编译期就能发现该错误。
第三是消除强制类型转换。泛型可以消除源代码中的许多强制类型转换,这样可以使代码更加可读,并减少出错的机会。
第四是向后兼容。支持泛型的Java编译器(例如JDK1.5中的Javac)可以用来编译经过泛型扩充的Java程序(Generics Java程序),但是现有的没有使用泛型扩充的Java程序仍然可以用这些编译器来编译。
3.7 这样的a.hashcode() 有什么用,与a.equals(b)有什么关系。
equals相等两个对象,则hashcode一定要相等。但是hashcode相等的两个对象不一定equals相等。
3.8 有没有可能2个不相等的对象有相同的hashcode。
有
3.9 Java中的HashSet内部是如何工作的。
对于 HashSet 而言,它是基于 HashMap 实现的,底层采用 HashMap 来保存元素
我们先通过 HashSet 最简单的构造函数和几个成员变量来看一下,证明咱们上边说的,其底层是 HashMap:
1 | private transient HashMap<E,Object> map; |
其实在英文注释中已经说的比较明确了。首先有一个HashMap的成员变量,我们在 HashSet 的构造函数中将其初始化,默认情况下采用的是 initial capacity为16,load factor 为 0.75。
HashSet 的实现
对于 HashSet 而言,它是基于 HashMap 实现的,HashSet 底层使用 HashMap 来保存所有元素,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,我们应该为保存到 HashSet 中的对象覆盖 hashCode() 和 equals()
构造方法
1 | /** |
add 方法
1 | /** |
如果此 set 中尚未包含指定元素,则添加指定元素。更确切地讲,如果此 set 没有包含满足(e==null ? e2==null : e.equals(e2)) 的元素 e2,则向此 set 添加指定的元素 e。如果此 set 已包含该元素,则该调用不更改 set 并返回 false。但底层实际将将该元素作为 key 放入 HashMap。思考一下为什么?
由于 HashMap 的 put() 方法添加 key-value 对时,当新放入 HashMap 的 Entry 中 key 与集合中原有 Entry 的 key 相同(hashCode()返回值相等,通过 equals 比较也返回 true),新添加的 Entry 的 value 会将覆盖原来 Entry 的 value(HashSet 中的 value 都是PRESENT),但 key 不会有任何改变,因此如果向 HashSet 中添加一个已经存在的元素时,新添加的集合元素将不会被放入 HashMap中,原来的元素也不会有任何改变,这也就满足了 Set 中元素不重复的特性。
该方法如果添加的是在 HashSet 中不存在的,则返回 true;如果添加的元素已经存在,返回 false。其原因在于我们之前提到的关于 HashMap 的 put 方法。该方法在添加 key 不重复的键值对的时候,会返回 null。
其余方法
1 | /** |
相关说明
- 相关 HashMap 的实现原理,请参考上面的点
- 对于 HashSet 中保存的对象,请注意正确重写其 equals 和 hashCode 方法,以保证放入的对象的唯一性。这两个方法是比较重要的,希望大家在以后的开发过程中需要注意一下。
4.0 什么是序列化,怎么序列化,为什么序列化,反序列化会遇到什么问题,如何解决。
序列化与反序列化是开发过程中不可或缺的一步,简单来说,序列化是将对象转换成字节流的过程,而反序列化的是将字节流恢复成对象的过程。序列化与反序列化是一个标准(具体参考XDR:外部数据表示标准 RFC 1014),它是编程语言的一种共性,只是有些编程语言是内置的(如Java,PHP等),有些语言是通过第三方库来实现的(如C/C++)。
使用场景
- 对象的持久化(将对象内容保存到数据库或文件中)
- 远程数据传输(将对象发送给其他计算机系统)
为什么需要序列化与序列化?
序列化与序列化主要解决的是数据的一致性问题。简单来说,就是输入数据与输出数据是一样的。
对于数据的本地持久化,只需要将数据转换为字符串进行保存即可是实现,但对于远程的数据传输,由于操作系统,硬件等差异,会出现内存大小端,内存对齐等问题,导致接收端无法正确解析数据,为了解决这种问题,Sun Microsystems在20世纪80年代提出了XDR规范,于1995年正式成为IETF标准。
Java中的序列化与反序列化
Java语言内置了序列化和反序列化,通过Serializable接口实现。
1 | public class Account implements Serializable { |
序列化兼容性
序列化的兼容性指的是对象的结构变化(如增删字段,修改字段,字段修饰符的改变等)对序列化的影响。为了能够识别对象结构的变化,Serializable使用serialVersionUID字段来标识对象的结构。默认情况下,它会根据对象的数据结构自动生成,结构发生变化后,它的值也会跟随变化。虚拟机在反序列化的时候会检查serialVersionUID的值,如果字节码中的serialVersionUID和要被转换的类型的serialVersionUID不一致,就无法进行正常的反序列化。
示例:将Account对象保存到文件中,然后在Account类中添加address字段,再从文件中读取之前保存的内容。
1 | // 将Account对象保存到文件中 |
由于在保存Account对象后修改了Account的结构,会导致serialVersionUID的值发生变化,在读文件(反序列化)的时候就会出错。所以为了更好的兼容性,在序列化的时候,最好将serialVersionUID的值设置为固定的。
1 | public class Account implements Serializable { |
序列化的存储规则
Java中的序列化在将对象持久化(序列化)的时候,为了节省磁盘空间,对于相同的对象会进行优化。当多次保存相同的对象时,其实保存的只是第一个对象的引用。
1 | // 将account对象保存两次,第二次保存时修改其用户名 |
输出结果:
1 | account2.name=Freeman |
所以在对同一个对象进行多次序列化的时候,最好通过clone一个新的对象再进行序列化。
序列化对单例的影响
反序列化的时候,JVM会根据序列化生成的内容构造新的对象,对于实现了Serializable的单例类来说,这相当于开放了构造方法。为了保证单例类实例的唯一性,我们需要重写resolveObject方法。
1 | /** |
控制序列化过程
虽然直接使用Serializable很方便,但有时我们并不想序列化所有的字段,如标识选中状态的isSelected字段,涉及安全问题的password字段等。此时可通过通过以下方法实现:
- 给不想序列化的字段添加static或transient修饰词:
Java中的序列化保存的只是对象的成员变量,既不包括static成员(static成员属于类),也不包括成员方法。同时Java为了让序列化更灵活,提供了transient关键字,用来关闭字段的序列化。
1 | public class Account implements Serializable { |
- 直接使用Externalizable接口控制序列化过程:
Externalizable也是Java提供的序列化接口,与Serializable不同的是,默认情况下,它不会序列化任何成员变量,所有的序列化,反序列化工作都需要手动完成。
1 | public class Account implements Externalizable { |
自己实现序列化/反序列化过程
public class Account implements Serializable {
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17private static final long serialVersionUID = 1L;
private String userName;
private transient String idcard;
private String password;
private void writeObject(ObjectOutputStream oos)throws IOException {
// 调用默认的序列化方法,序列化非transient/static字段
oos.defaultWriteObject();
oos.writeObject(idcard);
}
private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException {
// 调用默认的反序列化方法,发序列化非transient/static字段
ois.defaultReadObject();
idcard = (String)ois.readObject();
}}
关于Java序列化算法的详细介绍可参考:Java序列化算法透析
Java序列化注意事项
- 通过Serializable序列化的对象,在反序列化的时候,直接根据字节码构造对象,并不会调用对象的构造方法;
- 通过Serializable序列化子类时,如果父类没有实现Serializable接口,那么父类需要提供默认的构造方法,否则在反序列化的时候抛出java.io.NotSerializableException异常;
- 通过Externalizale实现序列化时,反序列化的时候需要调用对象的默认构造方法;
- 由于Externalizale默认情况下不会对任何成员变量进行序列化,所以transient关键字只能在Serializable序列化方式中使用;
数据交换协议
序列化与反序列化为数据交换提供了可能,但是因为传递的是字节码,可读性差。在应用层开发过程中不易调试,为了解决这种问题,最直接的想法就是将对象的内容转换为字符串的形式进行传递。具体的传输格式可自行定义,但自定义格式有一个很大的问题——兼容性,如果引入其他系统的模块,就需要对数据格式进行转换,维护其他的系统时,还要先了解一下它的序列化方式。为了统一数据传输的格式,出现了几种数据交换协议,如:JSON, Protobuf,XML。这些数据交换协议可视为是应用层面的序列化/反序列化。
JSON
JSON(JavaScript Object Notation)是一种轻量级,完全独立于语言的数据交换格式。目前被广泛应用在前后端的数据交互中。
语法
JSON中的元素都是键值对——key:value形式,键值对之间以”:”分隔,每个键需用双引号引起来,值的类型为String时也需要双引号。其中value的类型包括:对象,数组,值,每种类型具有不同的语法表示。
对象
对象是一个无序的键值对集合。以”{“开始,以”}”结束, 每个成员以”,”分隔。例如:
1 | "value" : { |
数组
数组是一个有序的集合,以”[“开始,以”]”结束,成员之间以”,”分隔。例如:
1 | "value" : [ |
值
值类型表示JSON中的基本类型,包括String,Number(byte, short, int, long, float, double), boolean。
1 | "name": "Freeman" |
==注意==:对象,数组,值这三种元素可互相嵌套!
1 | { |
对于JSON,目前流行的第三方库有Gson, fastjson:关于Gson的详细介绍,参考Gson使用教程
Protobuf
Protobuf是Google实现的一种与语言无关,与平台无关,可扩展的序列化方式,比XML更小,更快,使用更简单。
Protobuf具有很高的效率,并且几乎为主流的开发语言都提供了支持,具体参考Protobuf开发文档。
在Android中使用Protobuf,需要protobuf-gradle-plugin插件,具体使用查看其项目说明。
XML
XML(Extensible Markup Language)可扩展标记语言,通过标签描述数据。示例如下:
1 |
|
使用这种方式传输数据时,只需要将对象转换成这种标签形式,在接收到数据后,将其转换成相应的对象。
关于JAVA开发中对XML的解析可参考四种生成和解析XML文档的方法详解
数据交换协议如何选择
从性能,数据大小,可读性三方面进行比较,结果如下:
| 协议 | 性能 | 数据大小 | 可读性 |
|---|---|---|---|
| JSON | 良 | 良 | 优 |
| Protobuf | 优 | 优 | 差 |
| XML | 中 | 中 | 中 |
对于数据量不是很大,实时性不是特别高的交互,JSON完全可以满足要求,毕竟它的可读性高,出现问题容易定位(注:它是目前前端,app和后端交换数据使用的主流协议)。而对于实时性要求很高,或数据量大的场景,可使用Protobuf协议。具体数据交换协议的比较可参考github.com/eishay/jvm-…
