第一步,一定要明确 dp 数组的含义。对于两个字符串的动态规划问题,套路是通用的。
比如说对于字符串 s1 和 s2,一般来说都要构造一个这样的 DP table:
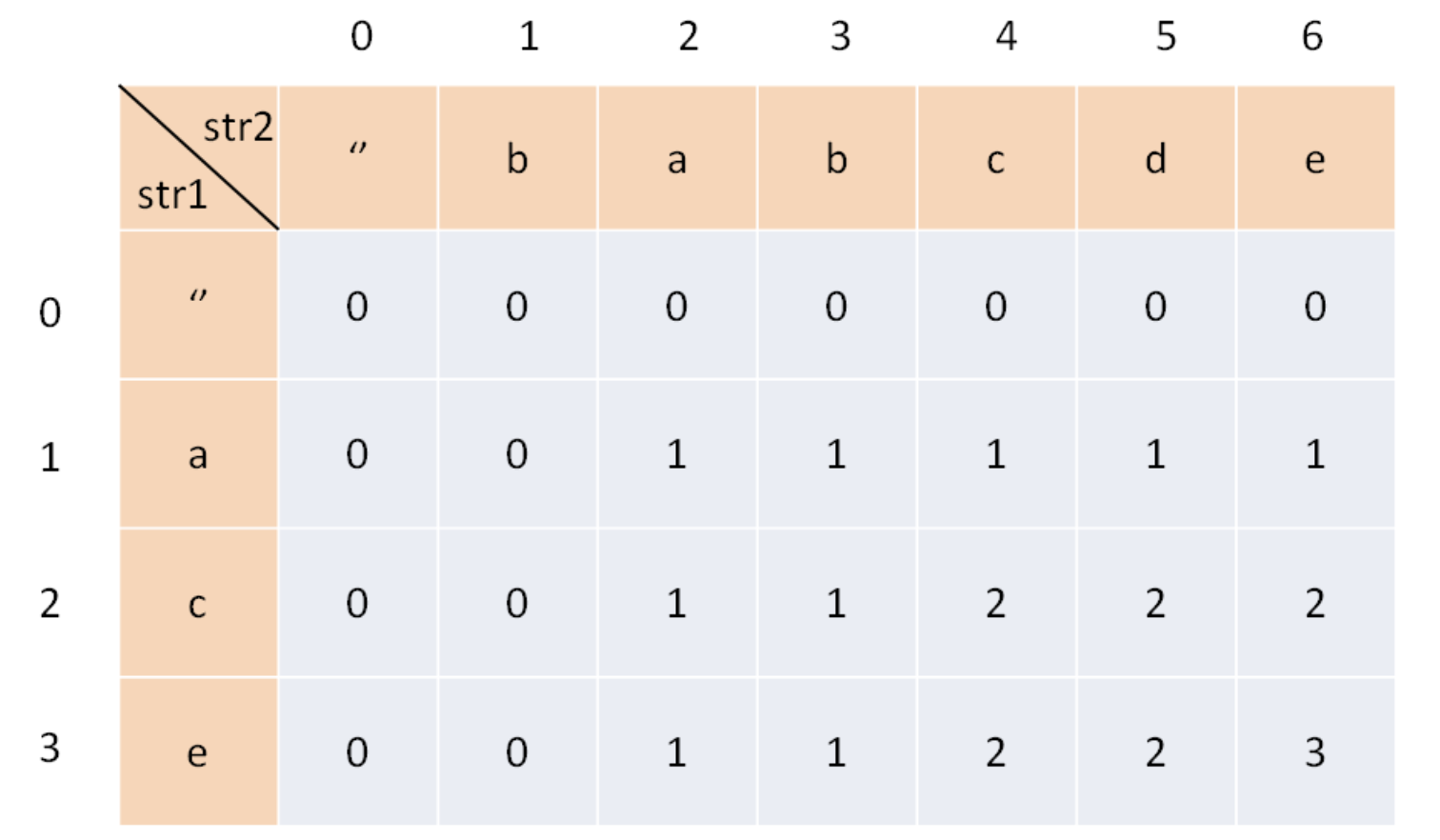
为了方便理解此表,暂时认为索引是从 1 开始的,待会的代码中只要稍作调整即可。其中,dp[i][j] 的含义是:对于 s1[1..i] 和 s2[1..j],它们的 LCS 长度是 dp[i][j]。
比如上图的例子,d[2][4] 的含义就是:对于 "ac" 和 "babc",它们的 LCS 长度是 2。最终想得到的答案应该是 dp[3][6]。
第二步,定义 base case。
让索引为 0 的行和列表示空串,dp[0][..] 和 dp[..][0] 都应该初始化为 0,这就是 base case。
比如说,按照刚才 dp 数组的定义,dp[0][3]=0 的含义是:对于字符串 "" 和 "bab",其 LCS 的长度为 0。因为有一个字符串是空串,它们的最长公共子序列的长度显然应该是 0。
第三步,找状态转移方程。
这是动态规划最难的一步
状态转移说简单些就是做选择,比如说这个问题,是求 s1 和 s2 的最长公共子序列,不妨称这个子序列为 lcs。那么对于 s1 和 s2 中的每个字符,有什么选择?很简单,两种选择,要么在 lcs 中,要么不在。
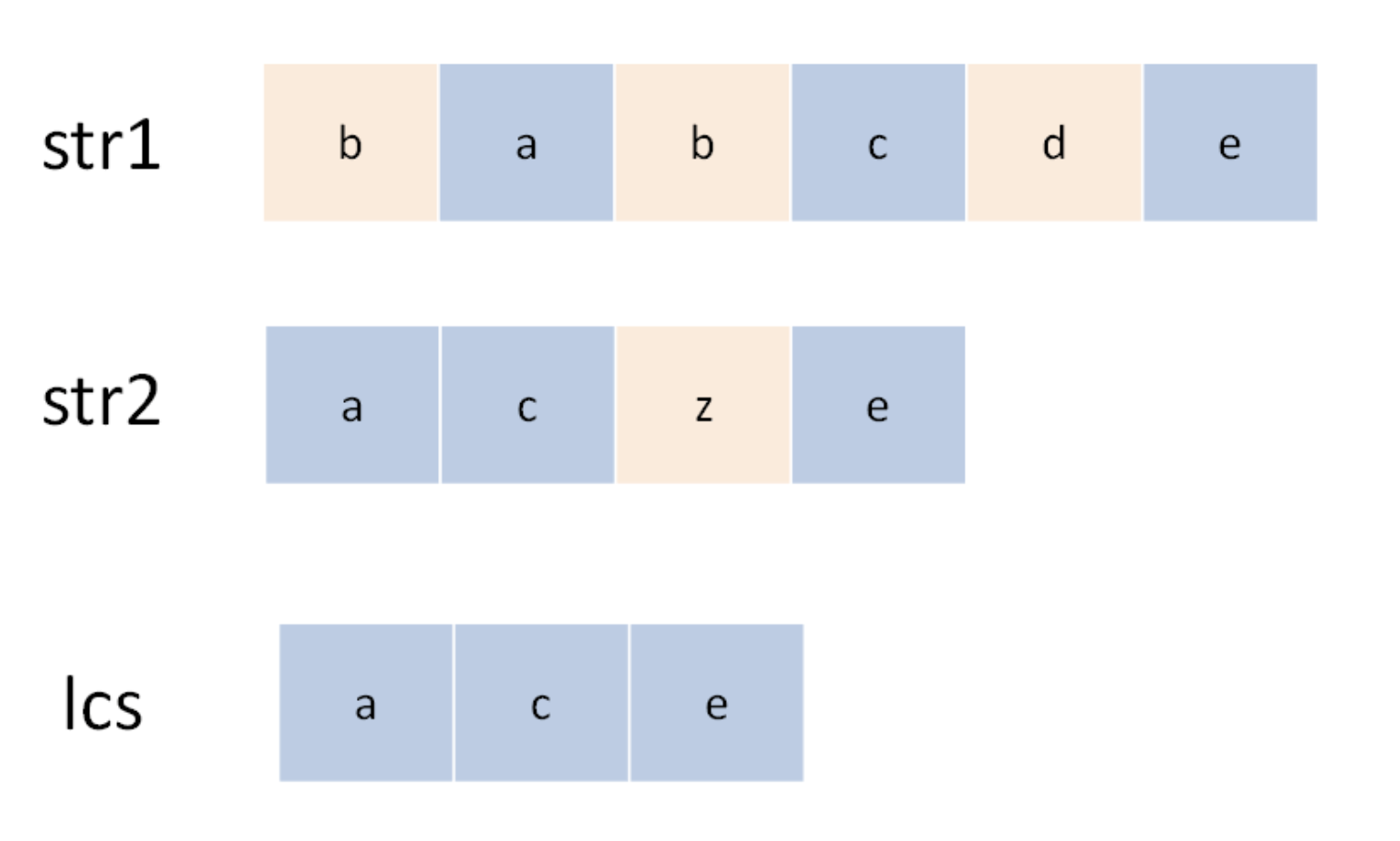
这个「在」和「不在」就是选择,关键是,应该如何选择呢?这个需要动点脑筋:如果某个字符应该在 lcs 中,那么这个字符肯定同时存在于 s1 和 s2 中,因为 lcs 是最长公共子序列嘛。所以本题的思路是这样:
用两个指针 i 和 j 从后往前遍历 s1 和 s2,如果 s1[i]==s2[j],那么这个字符一定在 lcs 中;否则的话,s1[i] 和 s2[j] 这两个字符至少有一个不在 lcs 中,需要丢弃一个。先看一下递归解法,比较容易理解:
1 | String str1; |
对于第一种情况,找到一个 lcs 中的字符,同时将 i j 向前移动一位,并给 lcs 的长度加一;对于后者,则尝试两种情况,取更大的结果。
其实这段代码就是暴力解法,我们可以通过备忘录或者 DP table 来优化时间复杂度,比如通过 DP table 来解决:
1 | int dp(String str1, String str2) { |
